이번 포스팅에서는 기초통계 테이블을 만들기 위해 사용되는 tableone 패키지를 소개해드리겠습니다.
우선 tableone 패키지를 설치한 후 불러오도록 합시다.
# install.packages('tableone')
require(tableone) # library(tableone)tableone의 createTableOne( ) 기능을 사용하여 mtcars 데이터를 요약해보도록 하겠습니다!
tbl1 <- CreateTableOne(
vars = c('cyl', 'mpg','hp','drat','wt','qsec','vs','am','gear','carb'), # 요약할 변수
factorVars = c('vs','am','gear'), # 범주형 변수 data=mtcars # 사용할 데이터셋
)
tbl1
createTableOne( )에는 파라미터들을 입력해주어야 합니다.
vars에는 데이터셋 중에서 요약하고 싶은 변수의 이름을, factorVars에는 요약하고자 하는 변수 중 범주형 변수의 이름을 입력합니다.
이 코드를 실행하게 되면, 왼쪽의 테이블처럼 깔끔한 테이블이 출력됩니다.
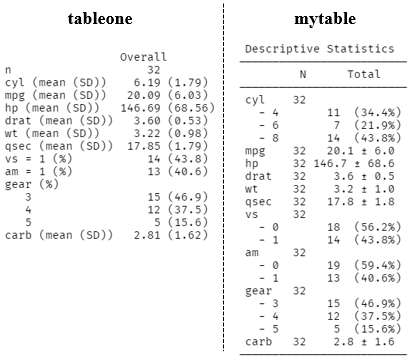
요약 테이블로 자주 사용되는 mytable과 비교해보았습니다. CreateTableOne이 왼쪽, mytable이 오른쪽입니다.
mytable과 다른 점은 범주가 두개인 경우 0이 아닌 1에 해당하는 경우의 결과값만 출력이 된다는 것입니다.
만약 범주형 변수의 모든 level의 결과를 출력하고 싶다면 다음과 같이 실행하면 됩니다.
print(tbl1, showAllLevels = TRUE) # 범주형의 모든 level 출력
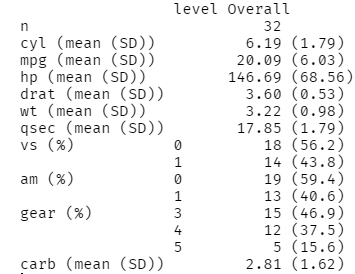
그런데 지금 결과를 보니, 범주형 변수들의 % 값은 소수점 1자리로 되어있고, 연속형 변수들은 소수점 2자리로 출력이 되었네요.
결과물을 소수점 한 자리로 통일하려면 다음과 같이 코드를 입력하면 됩니다.
print(tbl1,
showAllLevels = T,
contDigits = 1, # continuous (연속형) 변수의 자리수
catDigits = 1, # categorical (범주형) 변수의 자리수 설정 )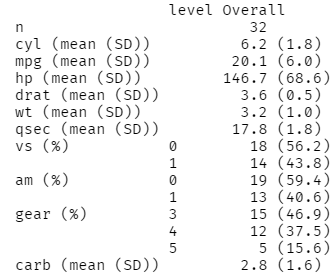
tableone을 통해 변수별 기초통계량을 확인할 수 있습니다.
가령 결측치는 어떻게 되는지, 중앙값과 최솟값, 최댓값, 4분위수도 필요할 때도 있을텐데요.
만약 이걸 일일이 다 코드로 쳐야 한다면 어떨까요?
min(mtcars$mpg)
max(mtcars$mpg)
median(mtcars$mpg)
summary(mtcars$mpg)
...모든 변수에 대해 저렇게 하나하나 코드를 실행하고 그 결과값을 입력한다면 굉장히 비효율적일 것입니다.
저렇게 노가다를 할 필요 없이 간단하게 아래의 코드를 실행해봅시다.
summary(tbl1)
결측치(miss) 뿐만 아니라 연속형 변수의 중앙값, 1분위수(p25), 3분위수(p75), 최소값(min), 최대값(max), 왜도(skew), 척도(kurt)도 확인할 수 있습니다.
한편 tableone에서도 그룹별로 기술통계 결과값을 출력할 수 있습니다.
tbl2 <- CreateTableOne( vars = c('mpg','hp','drat','wt','qsec','vs','am','gear','carb'),
factorVars = c('vs','am','gear'),
strata = 'cyl', # 하위그룹으로 나눌 변수
addOverall = TRUE, # 전체도 추가하기
data=mtcars )
tbl2
결과를 보시면, 실린더가 4개인 차량, 6개인 차량, 8개인 차량별로 결과값들이 잘 나타났습니다.
tableone의 장점은 전체 데이터셋의 기술통계 (Overall)와 하위그룹별 기술통계값을 동시에 출력할 수 있다는 것입니다.
자 그런데 오른쪽 마지막 열의 'test'는 비어있는데요.
이 test는 정규분포를 만족하지 않는 변수를 지정해줄 때, 출력이 되게 됩니다.
현재 출력된 p value는 정규성을 가정했을 때, 즉 데이터셋의 n수가 충분히 많다는 것을 가정했을 때의 결과입니다.
만약 데이터셋의 n수가 적어 정규성을 가정할 수 없기 때문에 비모수 검정을 해야한다고 했을 때는,
모수 검정에 적용되는 T-test나 Anova, 또는 chi-square 테스트가 아닌 Kruskal-Wallis test 나 Fisher's exact test가 이루어져야합니다.
실제로 mtcars의 데이터셋이 충분하지 않으므로 범주형 변수들은 모두 fisher test를, 연속형 변수들에는 kruskal-wallis test를 해보겠습니다.
print(tbl2, nonnormal = c('mpg','hp','drat','wt','qsec'), # 연속형 변수들: kruskal-wallis test
exact = c('vs','am','gear') # 범주형 변수들: fisher's exact test
)nonnormal 인자에는 연속형 변수들을, exact 인자에는 범주형 변수들을 지정해주었습니다.

test 결과 창에 연속형 변수들에는 nonnorm이, 범주형 변수들에는 exact가 붙은 것을 확인할 수 있습니다.
나중에 범주별로 matching 을 해주어서 Standard Mean Difference (SMD)를 확인하고 싶으신 분들은 "smd=T"를 추가해주시면 됩니다.
print(tbl2,
nonnormal = c('mpg','hp','drat','wt','qsec','carb'),
exact = c('vs','am','gear'), smd=T) # SMD 확인하기
자, 그런데 이 결과값들 역시 콘솔들로만 출력이 되는데요.
createTableOne()도 아무리 복사해서 붙여넣기 해봤자 테이블의 형태를 살릴 수 없습니다.
이를 해결하기 위해서는 kable( )을 이용하면 됩니다.
# install.packages('kableExtra')
require(kableExtra)
print(tbl2, nonnormal = c('mpg','hp','drat','wt','qsec','carb'),
exact = c('vs','am','gear'), smd=T) %>%
kableone() # tableone을 kable 형태로 바꾸기 %>%
kable_paper() # paper 형식으로 출력하기

R studio viewer 결과 창
Rstudio의 콘솔이 아닌 viewer 에 결과가 뜨게 됩니다.
이 녀석을 복사 (ctrl + c) 해서 붙여넣기(ctrl + v) 하면 테이블 형태가 그대로 보존됩니다.
이번 포스팅에서는 tableone 패키지의 createTableOne( ) 기능에 대해서 알아보았습니다.
createTableOne( ) 의 장점은 다음과 같습니다.
1. 전체, 하위그룹 결과 동시에 출력 가능
2. 세부 통계지표 출력 가능
3. 비모수 검정 결과 출력 가능
오늘 포스팅은 여기서 마치도록 하겠습니다.
감사합니다.
'R > Tables' 카테고리의 다른 글
| [r] gtsummary 다중회귀분석 테이블 만들기 (0) | 2022.04.28 |
|---|---|
| [r] gtsummary 로 기초통계 테이블 만들기 (0) | 2022.04.25 |
| [R table] gtsummary로 회귀분석 테이블 만들기 (0) | 2022.04.20 |



댓글